#Outline
- R-CNN, Fast R-CNN, Faster R-CNN 關係
- 流程圖
- BackBone
- RPN
- Anchor
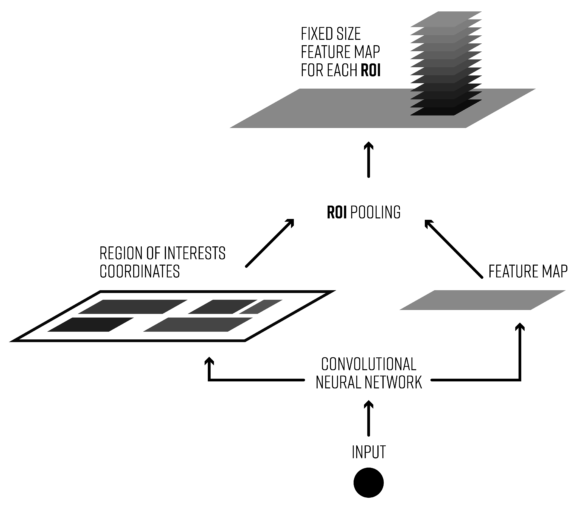
- ROI Pooling
- Bounding box regression
- 訓練
- 測試
R-CNN, Fast R-CNN, Faster R-CNN 關係
| R-CNN | 1.使用Selective Search 提取 Region Propose 2. 利用在ImageNet 訓練的CNN網路提取特徵 3.Bounding Box regression做邊框計算 4.由K個二分類SVM做分類(K= 任務分類數量) |
1.先利用SS提取2K個候選區(圖片) 2.每個候選區經過CNN取得特徵 3.特徵交由每個SVM計算分數以及Bbox Regressor調整邊框範圍 |
1.訓練步驟繁瑣(微調網絡+訓練SVM +訓練bbox) 2.訓練,測試均速度慢 3.訓練佔空間(每張圖片SS提取了2K個候選區) |
1.從DPM HSC的34.3%直接提升到了66%(mAP) 2.引入 CNN來做檢測問題 |
| Fast R-CNN | 1.使用Selective Search 提取 Region Propose 2. 利用在ImageNet 訓練的CNN網路提取特徵 3.Bounding Box regression配合多任務損失函數做邊框計算 4.Softmax做分類 |
1.先利用SS提取2K個候選區(邊框資訊) 2.整張圖用CNN取得特徵圖 3.將每個圖提取的邊框資訊(2K個候選區)對應到特徵圖上取得2K個特徵 4.透過ROI Pooling將不同大小的特徵統一成同樣大小 5.每個特徵交經過處理後由Softmax計算分數以及Bbox Regressor調整邊框範圍 |
1.依舊用SS提取RP(耗時2-3s,特徵提取耗時0.32s) 2.無法滿足實時應用,沒有真正實現端到端訓練測試 3.利用了GPU,但是RP是在CPU上運算 |
1.由66.9%提升至70% 2.每張圖像耗時約為3s。 |
| Faster R-CNN | 1.使用Region Propose Network 提取 Region Propose 2. 利用在ImageNet 訓練的CNN網路提取特徵 3. BBox Regressor 配合多任務損失函數做邊框計算 4.Softmax做分類 |
1.原圖先經過網路得到特徵圖 2.特徵圖經過RPN得到Proposed Region以及相應對分數 3. 採用NMS篩出Top-N個框(N=300) 4.透過ROI Pooling將不同大小的特徵統一成同樣大小 5.N個篩選出的框對應回原特徵圖取得N特徵 6.每個特徵交經過處理後由Softmax計算分數以及Bbox Regressor調整邊框範圍 |
1.還是無法達到Real-Time detection 2.計算量還是比較大,因為經過RPN得到多個Proposed Region,再對每個RP做Classification的話,還是有大量的重複計算。 |
1.提出了RPN,換掉了速度瓶頸的關鍵(SS),提高了檢測精度和速度 2.真正實現end-to-end的目標檢測框架 3.RPN生成bbox僅需約10ms。 |
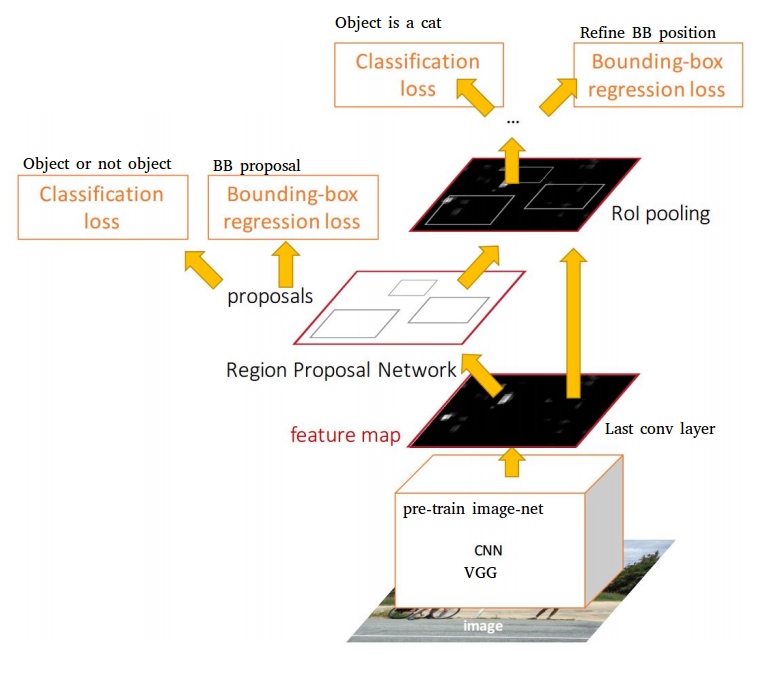
流程圖
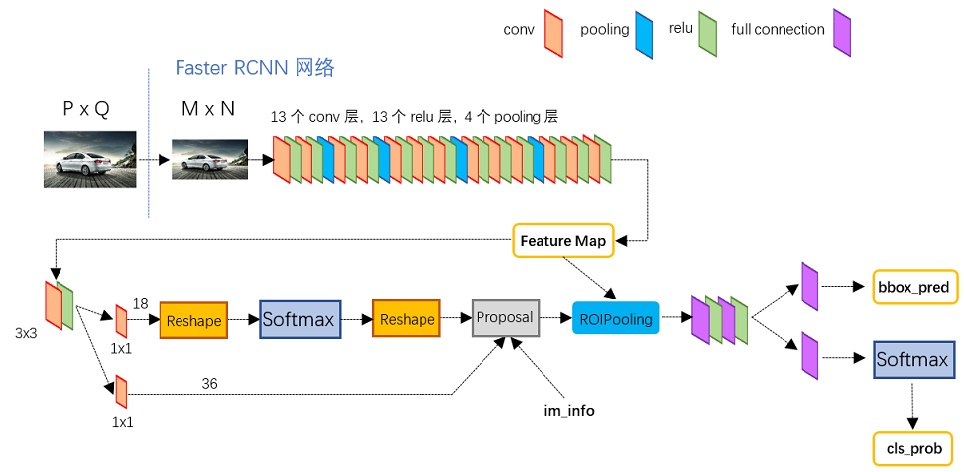
(1)輸入測試圖像;
(2)將整張圖片輸入CNN,進行特徵提取;
(3)用RPN生成建議窗口(建議),每張圖片生成300個建議窗口;
(4)把建議窗口映射到CNN的最後一層卷積feature map上;
(5)通過RoI pooling層使每個RoI生成固定尺寸的特徵圖;
(6)利用Softmax Loss(探測分類概率)和Smooth L1 Loss(探測邊框回歸)對分類概率和邊框回歸(Bounding box regression)聯合訓練。
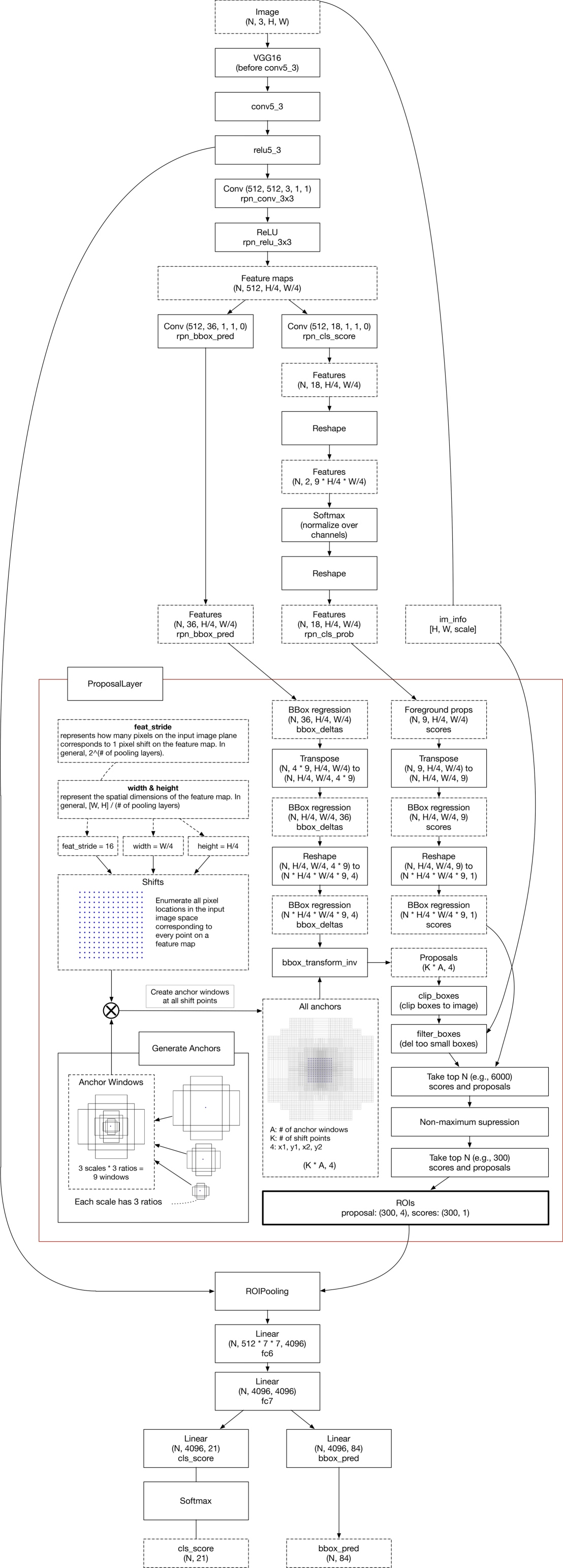
Backbone
原論文沒有特別提網路架構 一般來說是用ZF Net後來都是用VGG架構,甚至是後來用RESNET或是FPN
這裡就VGG16來討論,此結構中需要注意的是
所有的Conv層都是:kernel_size = 3,pad= 1
所有的Pooling都是:kernel_size = 2,stride= 2
Faster RCNN 中Conv層對所有的捲積都做了擴邊處理(pad = 1,即填充一圈0),導致原圖變為(M+2)x(N+2)大小,再做3x3卷積後輸出MxN
|
|
因此Conv層中的轉換次數層不改變輸入和輸出矩陣大小
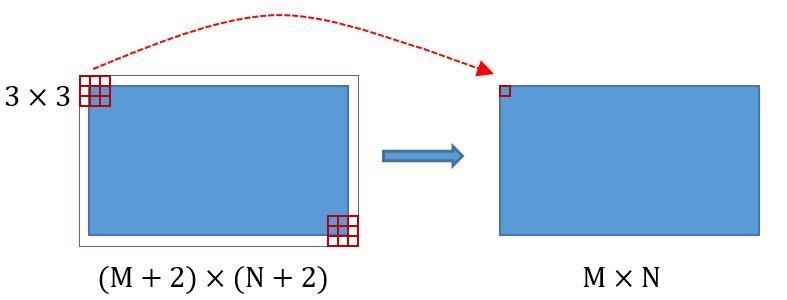
說明:卷積核mxm,輸入圖片WxH(擴邊之後的尺寸),則輸出圖片的尺寸是(W-m + 1)x(H-m + 1)
RPN
Anchor
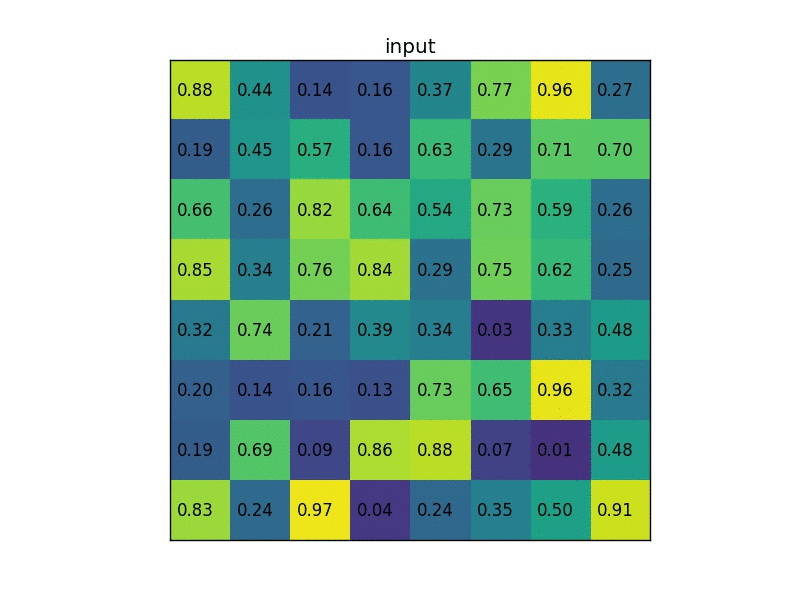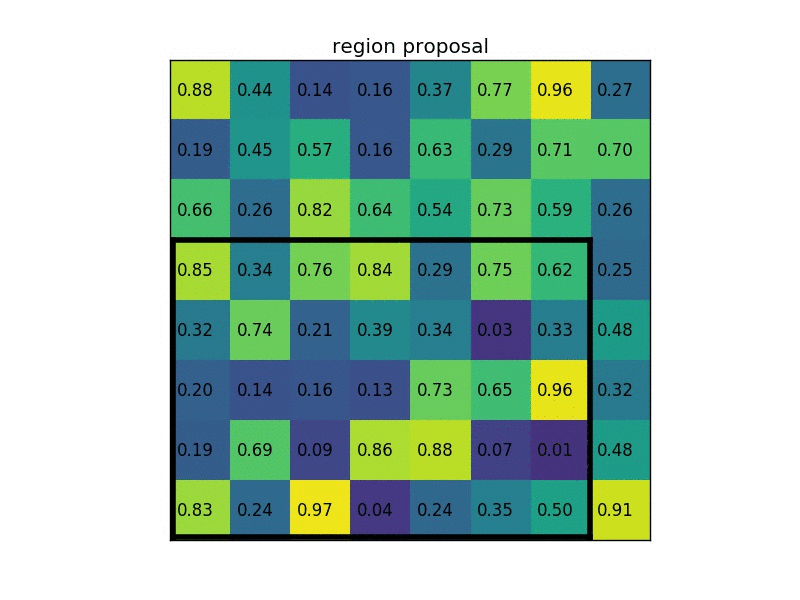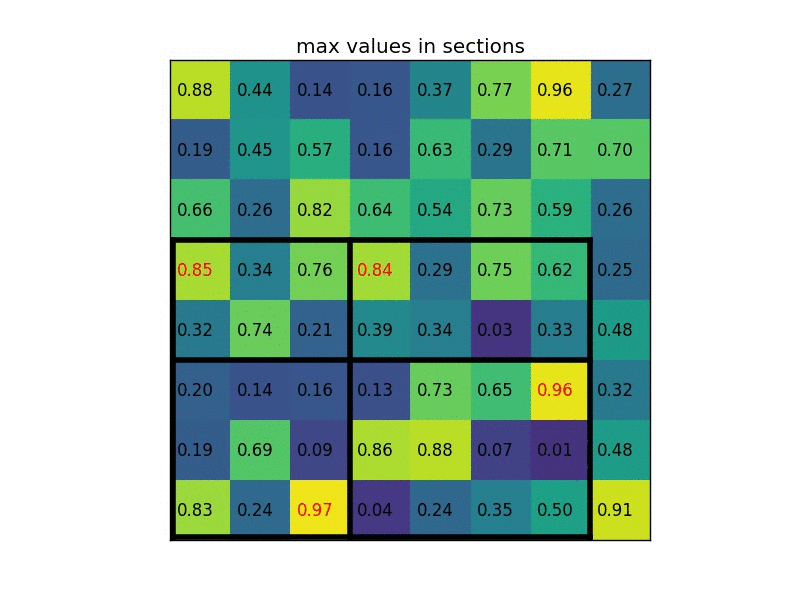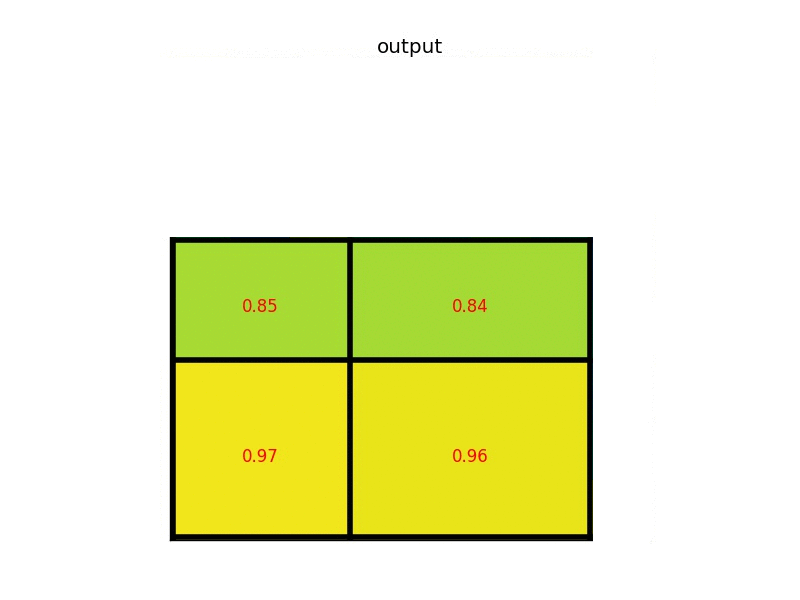
ROI POOLING
ROI POOLING 概念如下圖所示